From the Burrow
TaleSpire Dev Log 301
Today I’ve continued work on HeroForge, but first, let’s have a little multiplatform update.
Mac
The 10Gb ethernet gear arrived and worked brilliantly out of the box. The reason we bought these is two-fold:
- Our m1 iMacs only have 8GB of RAM, and that makes for a poor dev environment [0]
- We already have a nice setup on our windows machines. Given that we can cross-compile, it makes sense to build for Mac from there.
The big problem with building on Windows, however, is getting the result to the Mac. Even though it’s not big by modern standards, TaleSpire still takes a while to copy over a 1Gb network. In my experience so far, that delay is enough to hamper mental flow.
Re-enter the 10Gbe kit! I have now got the Windows box and the Mac directly connected via DAC, and I can copy an 8GB file between them faster than I can copy it from HDD to SSD on the same machine. [1]
I tested building directly to the Mac from Unity, and there was no drop in build time compared to building to the local one [2]. This test was the Windows build, however. So the next step was to start experimenting with builds for Apple Silicon.
The TLDR is there are still things to work out. For some reason, while building for Mac locally works, building directly to the remote folder fails silently[3]. Next, my build scripts are not producing the dll containing the Burst compiled code, whereas building from the Unity GUI does.
These aren’t too worrying though. Soon enough, we’ll have something that allows for fast iteration across these platforms. If it holds up under actual use, we’ll order some more for the team members who need them,
Oh, and Unity’s profiler works great across the link too!
Linux
Steam support has been back in touch and answered my remaining queries. The key points are:
- Steam’s store has no feature for us to treat running with Proton as the official Linux build (as I understand it)
- It is “not feasible” to bundle Proton with TaleSpire as a means to make a ‘native’ Linux build, which will show in the store as such.
What that means is that new Linux players will be buying the Windows version. Which is the same as it is now. Naturally, this works fine, but it’s a little less official than we would like.
We will simply have to make sure our messaging makes it clear what we officially support. It looks like the store page makes that easy.
HeroForge
Alright, back to the real work of the day.
The focus of today’s work has been two classes.
- HeroForgeDownloadManager: Which is responsible for downloading minis, converting them for TaleSpire, and writing the resulting asset packs to disk.
- HeroForgeManager: Which communicates with HeroForge (via our servers) and handles information about which minis are attached to the campaign.
The complexity comes from the number of moving parts:
- Anyone can add or remove minis from their HeroForge account
- They give/revoke TaleSpire access to talk to their HeroForge account
- They can give/revoke specific campaigns access to specific minis
- This information needs to be available on all clients regardless of whether they are actively playing or arrive later.
- The assets will download at different rates for different people
- There are systems (like fog-of-war) that need specific information about creatures to be on all clients at the same time to ensure that all clients compute the same results
My work today has been focused on making sure the flow of information guarantees that the systems have what they need at the correct times. So that, for example, the FoW system can correctly update vision for a creature even if the asset itself has not yet been downloaded.
It’s going well. I’ve got probably half a day more of wiring things up before I can start testing with real data and find all the places that are totally wrong :D [4]
Wrapping up
I’m pretty tired now, so I’m calling it a night.
Have a great weekend folks!
[0] Unity complains about low memory when trying to do something as simple as profile a dev build while the project is open in the editor. This clearly is unworkable. I don’t blame Unity too much for this, to be honest. 8GB is just not enough for development tools and games running on the same machine.
[1] The network copy took about 12 seconds, IIRC.
[2] In fact, it was 8 seconds faster, but I’m assuming that was an anomaly.
[3] The build appears to succeed, but there is no file.
[4] This will happen. The interconnectedness of all of this has meant it’s been a while since the code has been running. The compiler can only catch so much!
TaleSpire Dev Log 299
Hey folks,
Before we get started, the number of the dev-logs is not something we sync up with features or other announcements. We aren’t that media-savvy :P
Rendering nerdage
Ok, let’s get into things. In my last log, I was working away on HeroForge integration. However, on Thursday, I nerd sniped myself by watching A Deep Dive into Nanite Virtualized Geometry from Unreal and finally understanding some details of occlusion culling. It was just a little detail about building the early Hi-Z, but it got my mind wiring.
This, in turn, spun me off to this phenominal talk on clustered shading and shadows by Ola Olsson[0]. Even though we’ve managed to replicate Unity’s lighting approach without GameObjects, it simply doesn’t handle thousands of lights efficiently. This feels like something we should be able to integrate with Unity’s built-in rendering pipeline to improve non-shadow-casting lights.
On the subject of the built-in rendering pipeline, I should take this quick detour. The built-in rendering pipeline (sometimes called the BIRP) is the rendering pipeline that is enabled out of the box in Unity. They have, much more recently, added the SRP (scriptable rendering pipeline) that exposes much more control to developers. However:
- Porting a project to these is non-trivial and would require a lot of engineering and work on both TaleSpire and TaleWeaver
- They are not finished. In fact, SRP has been on hold for a while now as Unity works on the internals of DOTS and which we won’t go into here[1]
Because of this, we are looking at sticking with the BIRP until we simply outgrow it and have to invest in SRP. The good news is that it’s looking like we might be able to do more than I expected before having to take that plunge.
Ok back to code.
With the clustered shading talk fresh in my mind, I looked around to find more info about the technique. In the process, I found this post, which was a great read on clustering in itself and, I’m sure, will be very valuable in the future.
While musing back on the occlusion culling, it got me thinking about early-z passes in general, and I found this post. I don’t have anything to add about it, but it sparked plenty of ideas off in my head.
While the lights on our tiles and props currently don’t cast shadows, the sun, on the other hand, does, and rendering it is a significant portion of frame-time. Even if we could make our own version and use occlusion culling to optimize the process, I didn’t think we could integrate it without SRP [2].
After reading these two excellent articles on how Unity handles its cascaded shadow maps, I spotted something that might allow us to hook our own approach in. As shown in cutlikecoding’s article, Unity collects the shadows into a screen-space map after making the cascades. Not only is the shader that does that available [2] but Unity also gives an option in the project settings to replace it.

I’m hoping that this means we could make a version of this that integrates both the Unity shadow map and our own.
This is, of course, speculation at this point. But it was rather exciting nevertheless.
Performance
The above research included plenty I haven’t mentioned, and Friday had come to a close when I wrapped that up.
However, I was in a performance frame of mind, and I had a hankering to see what I could improve. To this end, I broke out the profiler and went looking.
Physics
One experiment I wanted to do was on how we use Unity’s Unity.Physics engine[3]. The engine is considered stateless, meaning you have to load in all the rigid-bodies you want to include in the simulation, each frame. There is an optimization, however, where you can tell it that the static objects are the same as last time, and thus it doesn’t have to rebuild the BVH (bounding volume hierarchy) or other internal data for statics.
As you can imagine, in a board with hundreds of thousands of tiles, loading that data into the physics engine starts taking a non-trivial amount of time.
The test board I was using was a monster that was shared on the discord and has many thousands of zones. We spawned a job for each copy, and I was concerned that the overhead was hurting the speed. To that end, I gathered all the pointers and lengths into an array and spawned fewer jobs to do the copying. It didn’t make a big difference, however. What did, was calling JobHandle.ScheduleBatchedJobs after scheduling every N jobs. It kept the workers fed well and gave enough of a speedup that I moved on to other things.
The next thing I wanted to test was, very crudely, would only copying the data from nearby zones be a win, given that the physics engine would have to rebuild the internal data for the statics more often? I quickly hacked this in and, to get a nice worst case, I forced the static rebuild on every frame.
I was, as expected, able to see an improvement, even with the rebuild costs. What I rediscovered, though, was how nice double-right clicking is to zip around the board. I noticed this because I wasn’t including zones from far away, so I couldn’t click them. This is not a show stopped by any means, but it is something I’d need to keep in mind when making a proper solution.
The proper solution would need to work out which zones need physics[4], and then minimize the number of times we need to rebuild the statics by being smart about when to drop zones from simulation.
During all this, I finally spotted something which had been bugging me for ages. I had never understood why we needed to copy the statics in every frame when, as far as I could see, they weren’t being modified. On re-reading their code, I finally noticed that they store dynamic and static rigid-bodies in the same array and that statics always came after dynamics. This meant that the indices from the BVH to the static bodies became incorrect whenever the number of dynamic rigid-bodies changed.
The upshot of this is that we can skip copying static objects if the zones have not been modified and the number of dynamic bodies has not changed since the last frame.
This gave a noticeable improvement! In the future, we’d probably want to fork their code and lay the data out in a way that lets us avoid copying more often. I’m also curious if we could develop a way to rebuild portions of the static data instead of all of it. Very exciting if possible.
General optimization
I remember an aphorism that goes roughly:
If you get a speedup of 100 or 1000 times, you probably didn’t start doing something smart, but instead stopped doing something dumb.
While we are definitely not seeing anything in the realm of 100 times speedups, I think we are still well in the land of ‘stopping doing dumb things’ when it comes to performance.
Over the course of the weekend, I did the following:
- Added an early out to culling when we are given a frustum which will definitely cull all assets
- Changed all Spaghet managers to share the ‘globals’ data for scripts. This meant we only had to update one.
- Noticed that zones checked every frame to see if they had missing assets that had finished loading. The zones now register for updates and unregister once all are loaded.
- Learned that calling GetNativeBufferPtr causes a synchronization with the rendering thread and that we should cache it instead.
- Refactored a bunch of update logic zones push data into collections for use in the next frame rather than scanning the zones to collect it
- Started using culling info to avoid uploading data for dynamic lights.
And other little things.
The result is that I was able to get a 50% improvement in framerate in my test on the monster board.
Please note: This does not mean 50% improvement in all boards. This is a result of a single test.
The speedups are probably more noticeable in large boards. However, even small improvements in smaller boards are worth it.[5]
Linux
Since our announcement that we would support macOS and Linux, I’ve been trying to get info from Steam regarding how best to ship with Proton.
For context, and as itsfoss explains, on Linux, you can choose to enable SteamPlay for ‘supported titles’ or ‘all other titles’.
We inquired about two things:
- How to be a supported title
- Whether we could pin a particular proton version as default so we could test against a known software
There has been a lot of back and forth over the last month, but I think we have the info now.
As to the version pinning question, the answer was no.
As to the first question, we got this feedback from support:
No problem, Chris! It’s a confusing piece slightly because of past history.
Before SteamDeck drove a bunch of additional effort on Proton, games did need to be “whitelisted” so to speak, and a customer playing games on Linux could take the step to say “let me try Windows games via proton even if they haven’t been whitelisted”
So, those customer-facing settings in the Steam client are still visible. But because we’ve made so much progress with Proton, the notion of that whitelisting doesn’t really make sense– we don’t update it, and we may phase it out of the Steam Linux client settings altogether at some point.
For you as a developer, there’s no longer a list to be added to– you’re good to go!
This is good and… well, not bad but interesting. We would like to make TaleSpire on Linux as obviously supported as on Windows. However, it seems like it will be behind an option for now, and we don’t have a way to indicate when we officially support it.
It might be a non-issue, as we Linux folks are used to having to jump through some hoops, but it is a little disappointing.
One option would be to bundle Proton with TaleSpire ourselves and ship it as a Linux native game. This would then appear in the store as such. This is a bunch more work, and feedback has indicated that it would still be good to allow people to use their own proton install if desired.
It’s an interesting situation, to be sure. We are still a little ways off from looking into the glaring Linux-specific bugs, so we don’t have to worry about an official release yet.
We’ll definitely keep you posted.
Wrapping up
That’s enough for today. Congrats if you made it all the way to the end!
Hope you have a lovely week, and I’ll be back soon with more dev-logs
Ciao.
[0] The lighting in the video isn’t great, and so I recommend following allow with the slides you can find here https://efficientshading.com/2016/07/12/game-technology-brisbane-presentation-2016/
[1] Not least because there is so little public information about it, and far too much conjecture online.
[2] Officially available from Unity Hub or here
[3] This is not the default physics engine in Unity but one which shipped with DOTs. It is stateless and impressively fast given what we throw at it.
[4] These places include:
- wherever a player is pointing with their cursor
- wherever any dice are
- wherever any moving creatures are
- etc
[5] Physics really shows this to be true. The longer a frame takes, the more time the physics engine has to simulate the next frame, and simulating more time takes more time. This means that speeding up non-physics code can mean the physics is using less time per frame.
TaleSpire Dev Log 298
Hi folks, time for another dev-log :)
HeroForge work continues
The first task was to replace the use of BlobAssetReference for serializing the HeroForge asset data, as yesterday we discovered that it was far too slow (~100ms on my machine).
That went smoothly and removed the most significant lag in our code. This allowed us to see all the stuff that was still too slow. From there, the bulk of the work was moving things to jobs. And making sure that, whenever we did have to do something on the main thread, we did it fast.
With asset processing/saving improved, I moved on to asset loading. The work was very similar until something cropped up that was rather surprising…

…Unity was taking a very long time to upload the textures. At first, I thought we were trying to access the texture’s data too soon after creation, so I put a delay between those steps. I think it helped a little, but the spike in the perf graph still remained.
I’ll spare you the details of all the tests and head-scratching, but I eventually stumbled on something by accident:

The first spike is the load with slow texture upload. All the little spikes are from running the same code in rapid succession. It seems that, after a delay, the first texture upload is slow, but uploads within a couple dozen frames of each other are fast.
I could make some wild guesses about what is happening, but to be honest, I just don’t know. For now, it’s enough to know that it’s not going to choke when batch processing, but it is rather unsettling.
There are two other spots where the loading code is slower than I’d like.
The first is that opening the asset file takes a couple of milliseconds. We can just move that out to the job that reads from that file.
The second is that the Texture2D constructors take a few milliseconds to run. Unfortunately, there isn’t I can do about that one as it’s not our code :(
Tomorrow I’ll start moving this into TaleSpire.
macOS support
About two weeks ago, Unity 2021.2 shipped. This is the first build of the editor to officially support Apple Silicon.
We had already tested TaleSpire in the 2021.2 beta and, on Windows, all looks good. This means we will probably upgrade the project in the coming weeks.
TaleSpire on macOS is still, of course, totally broken. But this was already known, and we covered the details back in this dev-log. We can, however, prepare our development environment. We are currently waiting on a fix to a Rider bug before we can code comfortably there[0]. However, a more ideal solution would be cross-compiling from our primary dev environment on Windows.
I’ve done my fair share of pushing builds across the network to other Windows test machines, and the time it takes to move a few GB really makes iteration times painful. If you’ve done much coding, I’m sure you know just how much difference iteration time makes to flow and thus how fast you can get things done.
Rather than replicate that joy on macOS, we have ordered some Sonnet 10Gb gear and will be testing to see if that makes for a tenable experience.
I’m rather excited about that!
That’s your lot
Ok, that’s all for tonight.
Hope you’ve had a good day.
Peace.
[0] I’m a big ol’ emacs nerd and would have loved to stay, but omnisharp or its integration are just too slow. I tried all the usual suspects, but Rider has unfortunately been the best for me by a fair margin so far.
TaleSpire Dev Log 297
Today my goal was to take the HeroForge asset processing code and turn it into the state machine used in TaleSpire.
This has gone reasonably well. The code is split up into a few steps, and the texture processing jobs seem to be running across many frames as hoped. This should have meant that our code was barely blocking the main thread. However, I got to learn something new instead!
It turns out that CreateBlobAssetReference is slow, really slow, like 100ms to allocate slow. This really surprised me until I realized that, while we load BlobAssetReferences in TaleSpire (and they load fast), we only create them in TaleWeaver, where subsecond delays don’t feel bad.
It’s only a minor issue, though, as we can just knock together our own little format. This will take a few hours tomorrow, and then I can look at the performance again. It remains to be seen how these long-running jobs will interact with the per-frame work that TaleSpire already has to do, but we’ll be able to check that once we get this all hooked up.
The really slow part is not our code, though, but GLTFast. On my machine, it’s taking 54ms per frame over 3 frames for it to load the data, and my machine is no slouch. I’ll definitely be looking into what we can quickly do to improve this[0], but not yet. I want to get all this code into TaleSpire and start wiring things up so I can see the gaps that still need filling.
Although Ree and I usually blog about our own stuff, I’m going to shout out his work today as I find it exciting. Ree’s currently refactoring the camera controller code, which is the kind of nuts-and-bolts improvement that has been stuck on our todo lists for ages. Not only does it make the codebase easier to work with, but it also takes us measurably closer to being able to give you all access to the cutscene tools that we use to make our trailers. The idea naturally being that you would be able to play these to your players in a session.
Alrighty, that’s the lot from me today. Seeya tomorrow.
[0] Hopefully, I’ve just not read the docs properly, and there’ll be some “skip horribly expensive operation” option. But if not, I’ll have to look at having it create views into the data rather than Unity objects and handle the raw data myself. Then at least we can kick it off to a separate thread and wait for it to finish.
TaleSpire Dev Log 296
Blimey, what a week.
I’ve been looking into converting heroforge models into a format we can consume. For our experiments, we were using some APIs that were either only available in the editor or not async and thus would stall the main thread for too long.
We get the assets in GLTF format, so we used GLTFUtility to do the initial conversion. We then needed to:
- pack the meshes together (except the base)
- resize some textures
- pack some texture together
- DXT compress the textures
- Save them in a new format which we can load quickly and asynchronously
The mesh part took a while as I was very unfamiliar with that part of Unity. Handling all possible vertex layouts would be a real pain, so we just rely on the models from HeroForge having a specific structure. This is a safe assumption to start with. Writing some jobs to pack the data into the correct format was simple enough, and then it was on to textures.
We are packing the metallic/gloss map with the occlusion map using a shader. We also use this step to bring the size of these textures down to 1024x1024. To ensure the readback didn’t block, I switched the code to use AsyncGPUReadback.
This did get me wondering, though. The GLTFUtility spends a bunch of time, after loading the data, spawning Unity objects for Meshes and Textures. Worse, because then use Texture.LoadImage it has to upload the data to the GPU too, which is totally unnecessary for the color and bump maps as we save those almost unchanged.
So I started attempting to modify the library to avoid this and make it more amenable to working with the job system.
Images in the GLTF format are (when embedded in the binary) stored as PNGs in ARGB32 format. LoadImage previously handled that for us, so I added StbImageSharp, tweaked it so as not to use objects, and wired that in instead.
Unfortunately, the further I went, the more little details made it tricky to convert. Even after de-object-orienting enough of the code and making decent progress, I was faced with removing functionality or more extensive rewrites. I was very aware of the time it was taking and the sunken cost fallacy and didn’t want to lose more time than I had to. I also noticed that some features in GLTF were not yet supported, and integrating future work would be tricky.
As I was weighing up options, I found GLTFast, another library that supports 100% of the GLTF specification purports to focus on speed. I had to rejig the whole process anyway, so it was an ok time to swap out the library.
In the last log, I talked about porting stb_dxt. stb_dxt performs compressions of a 4x4 block on pixels, but you have to write the code to process a whole image (adding padding as required). I wrote a couple of different implementations, one that collected the 4x4 blocks one at a time, and one that collected a full row of blocks before submitting them all. The potential benefit of the latter is that we can read the source data linearly. Even though it looked like I was feeding the data correctly, I was getting incorrect results. After a lot of head-scratching, I swapped out my port of stb_dxt for StbDxtSharp and was able to get some sensible results. This is unfortunate, but I had already reached Friday and didn’t want to waste more time. If we are interested, we can look into this another day.
Over the weekend, I did end up prodding this code some more. I was curious about generating mipmaps as the textures included didn’t have any. Even though the standard implementation is just a simple box filter, it’s not something I’ve written myself before, so I did :)
A bit of profiling of the asset loading shows mixed results. Reading the data from the disk takes many milliseconds, but we’ll make that async so that won’t matter. The odd thing is how long calls to Texture2D.GetRawTextureData are taking. I’m hoping it’s just due to being called right after creating the texture. I’ll try giving it a frame or two and see what it looks like then. The rest of the code is fast and amenable to being run in a job, so it should mean even less work on the main thread.
The processing code is going to need more testing. GLTFast is definitely the part that takes the longest. Once again, the uploading of textures to the GPU seems to be the biggest cost and is something we don’t need it to do… unless, of course, we want to do mipmap generation on the GPU. It’s all a bit of a toss-up and is probably something we’ll just leave until the rest of the HeroForge integration code is hooked up.
So there it is. A week of false starts, frustrations, and progress.
Have a good one folks!
TaleSpire Dev Log 295
Hey folks,
This morning I’m continuing my work on the HeroForge integration.
My current tasks revolve around loading the assets. For Dimension20, we had knocked together an importer which did the job but has two issues that don’t make it suitable for use inside TaleSpire:
- It didn’t need to worry about blocking the main thread
- It used some functionality from UnityEditor, which is not available at runtime.
This means we need to get coding :)
The first target to replace was EditorUtility.CompressTexture, which we use to compress the textures to DXT5/DXT1. You might at first think that you could just replace it with Texture2D.Compress, but it doesn’t have the same quality settings and (much worse) is not async.
So I went looking elsewhere. Luckily for us, the fantastic stb single file library project has just what the doctor ordered. stb_dxt is small, fast, and easy to read; however, it is in C, and while I could just include a dll, it looked like it would be easy to port to Burst’s HPC#.
So that’s what I got up to the other day. It was a straightforward task[0], and now I just need to write the code that drives the compression process[1].
Today my focus is on converting the format we get from HeroForge into something suitable for TaleSpire. We need to extract what we need, apply compression and store everything in a format suitable for fast async loading[2].
That’s it from me for now. I’ll be back with more as it develops.
Peace.
[0] I’ll probably release that code once I can confirm it’s all working.
[1] DXT compresses 4x4 pixel clusters, so stb_dxts’ API takes one cluster and appends the results to a buffer. The code to provide the clusters (with correct padding) is not part of stb_dxt.
[2] A small amount of work still needs to be done on the main thread as creatures use Unity’s GameObjects. However, most of it can be done without blocking.
TaleSpire Dev Log 294
Hey folks,
There has been a lot going on this past week, but just for fun, this morning, I took a few hours to look at performance.
The motivation came from a community member who posted some thoughts on performance issues they were seeing and shared the relatively beefy board they were testing.
I cracked out the profiler and saw what I expected. The frame-time was dominated by shadow rendering. Due to reasons[0], the shadows are culled on the CPU, and because of the sheer number of tiles, this was taking a long time[1].
Poking around, I saw lots of things that are already on my todo list for future improvements. What I didn’t expect was to spot something dumb.
BatchRendererGroup’s AddBatch method takes a Bounds which encapsulates all the instances. I had assumed that it would be used during culling to exclude batches that clearly didn’t need culling. However, this wasn’t the case.
Armed with this knowledge, I simply tweaked the culling job to check the bounds for the entire batch first, and only if it intersected the view frustum, to cull the individual instances. Naturally, this had a big effect.
When I first tested the board linked earlier, I was getting ~28fps. After this change, I was getting ~58fps. It dipped in some places in the board but never below 40fps, so this was still a nice win. [2]
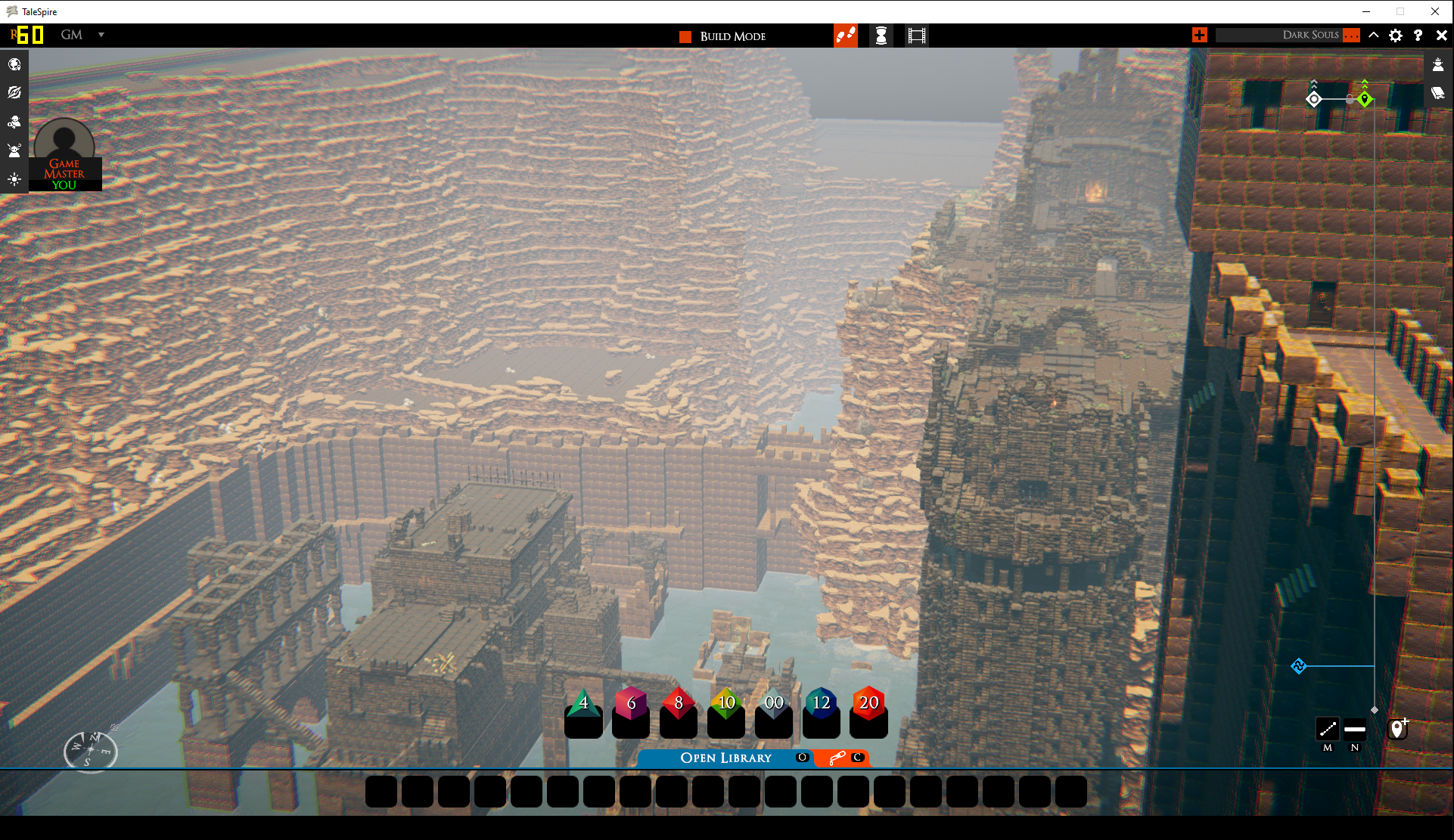
This will go out in a patch later this week.
While I was in the headspace, I also added some coarse culling to dynamic lights. It helped a little (and nudged the test board up to ~60fps), but doing more optimizing can wait for another day. [3]
Have a good one folks!
[0] Initially we tried to render all tiles via BatchRendererGroups. This failed, however, due to the (undocumented) face that `BatchRendererGroup’s were never meant to be used with Unity’s built-in render pipeline, and per-instance data was simply not supported.
To tackle this, we use compute shaders to perform frustum culling and populate the draw lists for DrawMeshInstancedIndirect. However, when using DrawMeshInstancedIndirect Unity doesn’t have enough information to do culling for you, and there are no hooks for doing this (In the built-in render pipeline, which we use).
So! We opted for a hybrid monstrosity. Shadows are handled via BatchRendererGroup, and we use our custom code to do the primary rendering.
BatchRendererGroup gives us nice hooks to perform culling, and we do these in Burst compiled jobs.
[1] This code no-doubt needs optimization too, but that’s for another day.
[2] Naturally, your mileage will vary. The effect will be most visible in larger boards where a higher percentage of the board is off-screen at any given time. Also, I’m running an AMD threadripper on my dev machine, so it inflates numbers a bit. However, this change will improve performance on all machines regardless of CPU as it’s simply doing less work :)
[3] The next big candidate for performance improvement is physics. I’m pretty confident that we can be smarter about what assets are involved in the simulation of each frame. Cutting down the number of assets included has the potential to help quite a bit.
TaleSpire Dev Log 291
This dev-log is an update from just one of the developers. It does not aim to include all the other things that are going on.
Hi everyone!
Just a quick warning. This is just a regular dev log, no big news in here.
Things have been good recently, but there are a lot of spinning plates to keep track of.
server issues
We had a server issue last week that stemmed from a database setting I hadn’t realized was enabled. The setting was to apply minor DB patches automatically. I had missed this, and so when the system obediently upgraded the DB, the server lost connection and got a tad confused.
Naturally, we want to schedule these patches explicitly so that the setting has been corrected.
Backend isn’t my strongest suit, so I’m reading and looking into the best way to handle this in the future. One likely portion of this is adding a ‘circuit breaker’ in front of the DB connection pool.
WebRTC
Unity has a rather interesting WebRTC package in the works, so I’ve been studying this topic again. We know we’d like to have audio and video chat in the future. Ideally, this would be p2p, but (IIRC) you’d be lucky to get NAT traversal to work for more than 85% of people, so this is usually paired with a TURN server to act as a relay for those folks.
That, of course, means handling the cost of such a server, and more importantly, the fees for the data going through it.
By default, p2p would imply a bidirectional connection between pair of players. So if you have ten people, you are sending the same data 10 times to different places. What many video providers opt for instead is to have servers that mix the feeds for you, so you only have one bidirectional connection. However, naturally, that means you are no longer p2p, and the server’s requirements (and thus costs) are MUCH higher than a simple relay server.
Lots to think about here. We’ll likely focus on p2p (with TURN fallback) when we start, but we’ll see how it evolves.
Performance
Performance work is never done, and we know that we need to do a lot to try and support both larger maps and lower-end machines. This past week my brain had latched onto this, so I spent a good deal of time reading papers and slides from various games to try and learn more of what contemporary approaches are.
Not much concrete to say about this yet. I know I have a lot to learn :P
Other
We had an internal play session the other day, which was a lot of fun and resulted in another page of ideas of potential improvements.
I’ve been working on HeroForge a bit, too, of course. I’m not satisfied with our backend design, so I need to focus on that more this week.
Hmm yeah, I think that’s most of it. Last week was very research-heavy, so I hope I end up coding more in this one.
The above is, of course, just me. The others have been making all manner of assets for future packs, which is both super exciting to see but also agonizing as it’s not time to show them publicly yet.
I hope you are all well. Have a good one folks!
TaleSpire Dev Log 290
Hi folks, just a quick log today to say that I’m [Baggers] taking a week off to relax. The rest of the team are still around, of course, so you’ll still be getting your regular scheduled programming :)
The last few weeks have felt great as bookmarks, links, and bugfixes have been shipping. Work on persistent emotes has been picking up again behind the scenes, and the assets in the pipeline are super exciting.
I hope you all have a great week.
Seeya!
TaleSpire Dev Log 289
Well, naturally, the biggest excitement in my day has been seeing the Dimension20 trailer go public, but code is also progressing, so I should talk about that.
Buuuuut I could watch it one more time :D
RIGHT! Now to business.
I started by looking into markers. Oh, actually, one little detail, soon you will be able to give markers names, at which point they are known as bookmarks. I’m gonna use those names below, so I thought I should mention that first.
Currently, markers are pulled when you join a specific board, and we only pull the markers for that board. To support campaign-wide bookmark search, we want to pull all of them when you join the campaign and then keep them up to date. This is similar to what we do for unique creatures, so I started reading that code to see how it worked.
What I found was that the unique creature sync code had some legacy cruft and was pulling far more than it needed to. As I was revisiting this code, it felt like time for a bit of a cleanup, so I got busy doing that.
As I was doing that, it gave me a good opportunity to add the backend data for links, which soon will allow you to associate an URL with creatures and markers. So I got stuck in with that too.
Because I was looking at links, it just felt right to think about the upcoming talespire://goto/ links, which will allow you to add a hyperlink to a web page that will open TaleSpire and take you to a specific marker (switching to the correct campaign and board in the process). After thinking about what the first version should be, I added this into the mix.
So now things are getting exciting. I’ve got a first iteration of the board-panel made for gms…
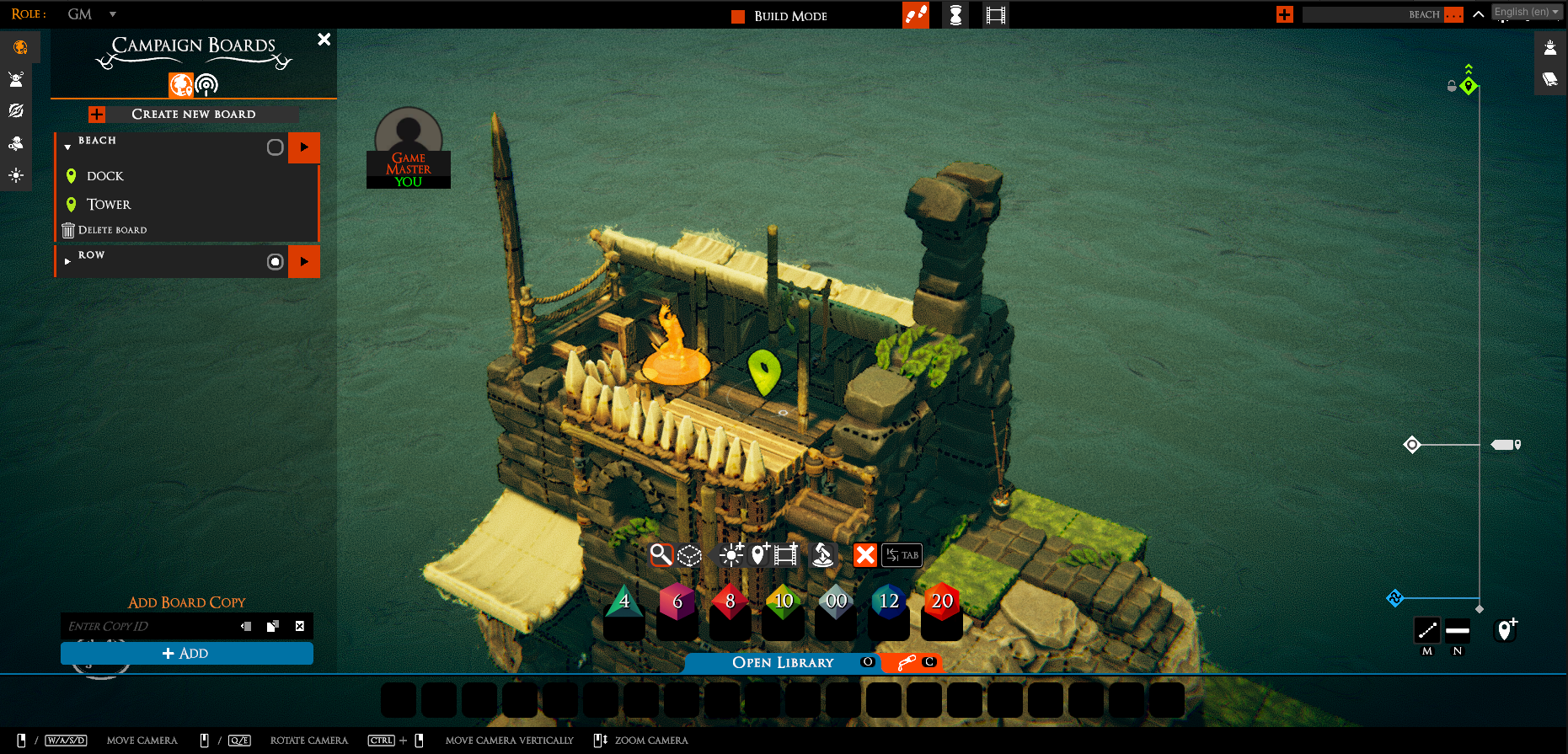
NOTE: I’ll be adding bookmark search soon
We can add names to markers to turn them into bookmarks. And you can get a talespire://goto link from their right-click menu.
I’ve got switching between campaigns working, but I need to do some cleanup on the “login screen to campaign” transition before I can wire everything up.
TLDR:

It would be great to ship all this late next week, but I’m not sure if that’s overly optimistic. We’ll see how the rest of it (and the testing) goes.
Until next time, Peace.